Machine Learning
Web Development
Django
Flask
AWS
Python
DevOps
Docker
Kubernetes
CI/CD
Scripting
More
Terraform
NLP
Linuxify
Nepal - Covid-19 Prediction models using different ML algorithms
Updated on Dec. 20, 2024, 10:18 p.m., by:
sagar
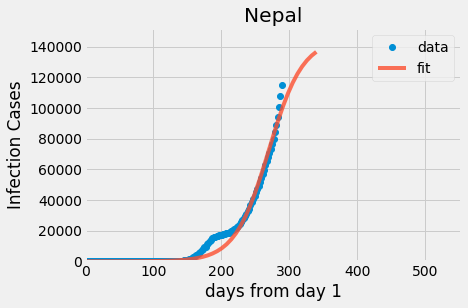
I am using a sigmoidal function to fit the historical data of Covid-19 and predict or forecast. And also use LinearRegression and RandomForestRegressor to predict. I thought of a sigmoidal function first because China's data resembled a sigmoidal shape. Therefore, I try to fit sigmoid functions onto Nepal also. **Step-1:Load dataset from s3 (download from [https://covid.ourworldindata.org/data/owid-covid-data.csv](https://covid.ourworldindata.org/data/owid-covid-data.csv))** import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') df1=pd.read\_csv('s3://sagemaker-studio-im065hy7nj/owid-covid-data.csv') #df1.head(5) df1.columns **Step-2: Subsetting only those rows that have "NPL" in the "location" column and plot y-axis total\_cases over x-axis as day-count.** Nepal\_df = df1\[df1\['location'\]=='Nepal'\].groupby('date')\[\['total\_cases','total\_deaths'\]\].sum() Nepal\_df\['day\_count'\] = list(range(1,len(Nepal\_df)+1)) ydata = Nepal\_df.total\_cases xdata = Nepal\_df.day\_count Nepal\_df\['rate'\] = (Nepal\_df.total\_cases-Nepal\_df.total\_cases.shift(1))/Nepal\_df.total\_cases Nepal\_df\['increase'\] = (Nepal\_df.total\_cases-Nepal\_df.total\_cases.shift(1)) \# Nepal\_df = Nepal\_df\[Nepal\_df.total\_cases>100\] plt.plot(xdata, ydata, 'o') plt.title("Nepal") plt.ylabel("Population Infected") plt.xlabel("Days") plt.show() **Output:** [](https://www.blogger.com/blog/post/edit/2875741694909600015/6667143551291784996#) **Step-3: Sigmoidal Function:** ** from scipy.optimize import curve\_fit import pylab def sigmoid(x,c,a,b): y = c\*1 / (1 + np.exp(-a\*(x-b))) return y xdata = np.array(\[1, 2, 3,4, 5, 6, 7\]) ydata = np.array(\[0, 0, 13, 35, 75, 89, 91\]) popt, pcov = curve\_fit(sigmoid, xdata, ydata, method='dogbox',bounds=(\[0.,0., 0.\],\[100,2, 10.\])) print(popt) x = np.linspace(\-1, 10, 50) y = sigmoid(x, \*popt) pylab.plot(xdata, ydata, 'o', label='data') pylab.plot(x,y, label='fit') pylab.ylim(\-0.05, 105) pylab.legend(loc='best') pylab.show() ** [](https://www.blogger.com/blog/post/edit/2875741694909600015/6667143551291784996#) Sigmoid function, Here is a snap of how I learnt to fit Sigmoid Function - y = c/(1+np.exp(-a\*(x-b))) and 3 coefficients \[c, a, b\]: * c - the maximum value (eventual maximum infected people, the sigmoid scales to this value eventually) * a - the sigmoidal shape (how the infection progress. The smaller, the softer the sigmoidal shape is) * b - the point where the sigmoid start to flatten from steepening (the midpoint of sigmoid, when the rate of increase start to slow down) **Step-4: Since our dataset doesn't have a recovered cases column so I am gonna import and read the next dataset** df2 = pd.read\_csv('s3://sagemaker-studio-im065hy7nj/time\_series\_covid19\_recovered\_global.csv') \# Extract list of values of 'recovered' column and insert that column to our first data-subset with proper arrangement. \# Since few pairs of row doesn't exist in column of new dataset, so we gonna manually add values referencing other sites. list(df2.iloc\[172, 4:\]) input\_values = \[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 4, 4, 4, 7, 10, 11, 12, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 22, 22, 31, 31, 31, 33, 33, 35, 35, 36, 36, 36, 36, 37, 45, 49, 70, 70, 87, 112, 155, 183, 187, 206, 219, 220, 221, 266, 278, 290, 333, 365, 467, 488, 584, 674, 861, 877, 913, 974, 1041, 1158, 1167, 1186, 1402, 1578, 1772, 2148, 2224, 2338, 2650, 2698, 2834, 3013, 3134, 3194, 4656, 5320, 6143, 6415, 6547, 6811, 7499, 7752, 7891, 8011, 8442, 8589, 10294, 10328, 11025, 11249, 11534, 11637, 11695, 11868, 12477, 12684, 12840, 12947, 13053, 13128, 13754, 13875, 14021, 14248, 14399, 14492, 14603, 14961, 15026, 15156, 15389, 15814, 16313, 16353, 16493, 16664, 16728, 16837, 17077, 17201, 17335, 17495, 17580, 17700, 17964, 18214, 18350, 18631, 18806, 19119, 19504, 20073, 20242, 20555, 20822, 21410, 22178, 23290, 24207, 25561, 27127, 28941, 30677, 32964, 33882, 35700, 36672, 37524, 38697, 39576, 40638, 41706, 42949, 43820, 45267, 46233, 47238, 48061, 49954, 50411, 51866, 53013, 53898, 54640, 55371, 56428, 57389, 60696, 62740, 64069, 65202, 67542, 68668, 71343, 73023, 74252, 75804, 77277, 78780, 80954\] len(input\_values) **step-5: Creating new subset with required columns and rows only:** in\_df1 = df1\[df1\['location'\]=='Nepal'\].groupby('date')\[\['total\_cases', 'new\_cases', 'total\_deaths', 'new\_deaths', 'total\_tests'\]\].sum().reset\_index(False) in\_df1\['recovered'\]= np.array(input\_values).copy() in\_df1\['Active'\]=in\_df1\['total\_cases'\]-in\_df1\['new\_deaths'\]-in\_df1\['recovered'\] \# in\_df1 = in\_df1\[in\_df1.Active>=20\] in\_df1.head(10) in\_df1.isnull().sum() **Step-6: Sigmoidal fitting** in\_df1\['day\_count'\] = list(range(1, len(in\_df1)+1)) in\_df1\['increase'\] = (in\_df1.total\_cases-in\_df1.total\_cases.shift(1)) in\_df1\['rate'\] = (in\_df1.total\_cases-in\_df1.total\_cases.shift(1))/in\_df1.total\_cases def sigmoid(x,c,a,b): y = c\*1 / (1 + np.exp(-a\*(x-b))) return y xdata = np.array(list(in\_df1.day\_count)\[::2\]) ydata = np.array(list(in\_df1.total\_cases)\[::2\]) \# population=29136808 \# popt, pcov = curve\_fit(sigmoid, xdata, ydata, method='dogbox',bounds=(\[0., 0., 0.\], \[population, 6, 180.\])) \# print(popt) **Step-7: Prediction Using Manual sigmoidal fitting:** ====================================================== import pylab est\_a = 145000 est\_b = 0.04 est\_c = 270 x = np.linspace(\-1, Nepal\_df.day\_count.max()+50, 50) y = sigmoid(x,est\_a,est\_b,est\_c) pylab.plot(xdata, ydata, 'o', label='data') pylab.plot(x,y, label='fit',alpha = 0.8) pylab.ylim(\-0.05, est\_a\*1.05) pylab.xlim(\-0.05, est\_c\*2.05) pylab.legend(loc='best') plt.xlabel('days from day 1') plt.ylabel('Infection Cases') plt.title('Nepal') pylab.show() print('model start date:',Nepal\_df\[Nepal\_df.day\_count==1\].index\[0\]) print('model start infection:',int(Nepal\_df\[Nepal\_df.day\_count==1\].total\_cases\[0\])) print('model fitted max infection at:',int(est\_a)) print('model sigmoidal coefficient is:',round(est\_b,2)) print('model curve stop steepening, start flattening by day:',int(est\_c)) print('which is date:', Nepal\_df\[Nepal\_df.day\_count==int(est\_c)\].index\[0\]) print('model curve flattens by day:',int(est\_c)\*2) display(Nepal\_df.head(3)) display(Nepal\_df.tail(3)) [](https://www.blogger.com/blog/post/edit/2875741694909600015/6667143551291784996#) [](https://www.blogger.com/blog/post/edit/2875741694909600015/6667143551291784996#) **Nepal,** * The b coefficient is 270, which means that the model starts to flatten 270 days, after the 25th of September, and really flatten significantly after 540 days. * The c coefficient is 145000, which is the predicted amount of infected people. * The coefficient is 0.04 is smaller than China's 0.22, which means the sigmoid is even softer in China. This means that Nepal will take even longer than China to fight Covid-19. From this, its seen that in Nepal if the graph goes like that: max Active case: 145000, curve stop steepening, start flattening by day: 270, which is: 2020-09-25, the curve flattens by day: 540 =========================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================== **Linear Regression and Random Forest for prediction:** ======================================================= **For this part, please go through sourcecode with explanations:** [https://colab.research.google.com/drive/1uKgB3L-7C5OtuhEdr0W1g2F-U3yV84vA#scrollTo=mYLbmyLGAFE\_](https://colab.research.google.com/drive/1uKgB3L-7C5OtuhEdr0W1g2F-U3yV84vA#scrollTo=mYLbmyLGAFE_)
SHARE :
Write your comment
Name
*
Email
Body
*
submit
0 comments
No comments yet. 😀
Category
AI-ML
Django
Python
Linuxify
Terraform
NLP
DevOps
AWS
others
Tags
Tags:
Covid-19
,
ML
,
AI
Similar posts
AI Chatbot
GAN(VQGAN) + CLIP Architecture
Latest posts
How to Resize EC2 EBS Volume Without Any Downtime (Disk Space)
Building a Docker container registry with Python
Multi-Cloud Deployments with Terraform and Packer
Subscribe to my RSS feed
Most commented posts
OpenVPN Access Server(self-hosted) set-up on AWS EC2
Gmail with Custom Domain using Cloudflare
Django, Postgres, Gunicorn, Nginx with Docker (Part-1)
Multi-Cloud Deployments with Terraform and Packer
Creating and Managing Infrastructure on Different Cloud Providers